Improving text representation has attracted much attention to achieve expressive text-to-speech (TTS). However, existing works only implicitly learn the prosody with masked token tasks, which leads to low training efficiency and difficulty in prosody modeling. We propose CLAPSpeech, a cross-model contrastive pre-training framework that learns from the prosody variance of the same text token under different contexts. Specifically, 1) with the design of a text encoder and a prosody encoder, we encourage the model to connect the text context with its corresponding prosody pattern in the joint multi-model space; 2) we introduce a multi-scale pre-training pipeline to capture prosody patterns in multiple levels. 3) we show how to incorporate CLAPSpeech into existing TTS models for better prosody. Experiments show that CLAPSpeech improves the prosody prediction of TTS methods and outperforms other representation learning baselines. We also deeply analyze the principle behind the performance of CLAPSpeech. Ablation studies demonstrate the necessity of each component in CLAPSpeech.
Audio Samples
We provide the audio samples generated by the TTS systems of LJSpeech (a single-speaker English dataset) and LibriTTS (a multi-speaker English dataset). We use FastSpeech 2 as the prediction-based (PB) TTS baseline, and use PortaSpeech as the variation-based (VB) TTS baseline.
LJSpeech (English, single-speaker)
"The Chronicles of Newgate, Volume 2. By Arthur Griffiths. Section 4: Newgate down to 1818."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
"Prisoners were committed to it quite without reference to its capacity."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
"No steps taken to reduce the number of committals, and the governor was obliged to utilize the chapel as a day and night room."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
"And debtors might practically have as much as they liked, if they could only pay for it."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
"For this and other acts of misconduct there was the discipline of the refractory ward, or "strong room" on the debtors' side."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
LibriTTS (English, multi-speaker)
"If at first you don't succeed, try try again."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
"He was, however, driven to resolve that he must go direct to Sophie, as otherwise, he could find no means of doing as he had promised."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
"The stove had a lot of little openings. In one he would put an egg, in another some coffee, and another a piece of meat, and in the fourth some water."
GT
PB baseline
PB + BERT
PB + A3T
PB + CLAPSpeech
wav
GT (voc.)
VB baseline
VB + BERT
VB + A3T
VB + CLAPSpeech
wav
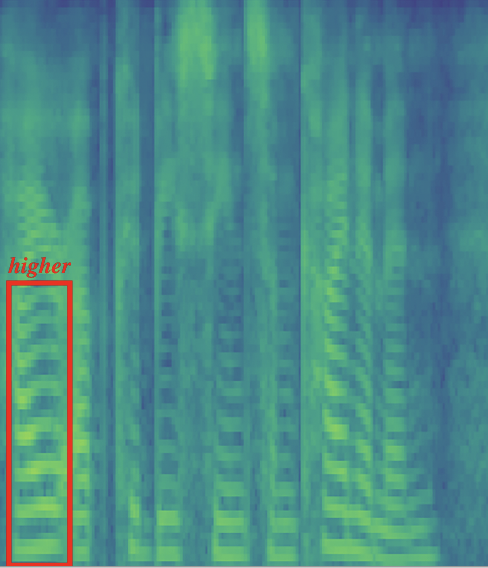
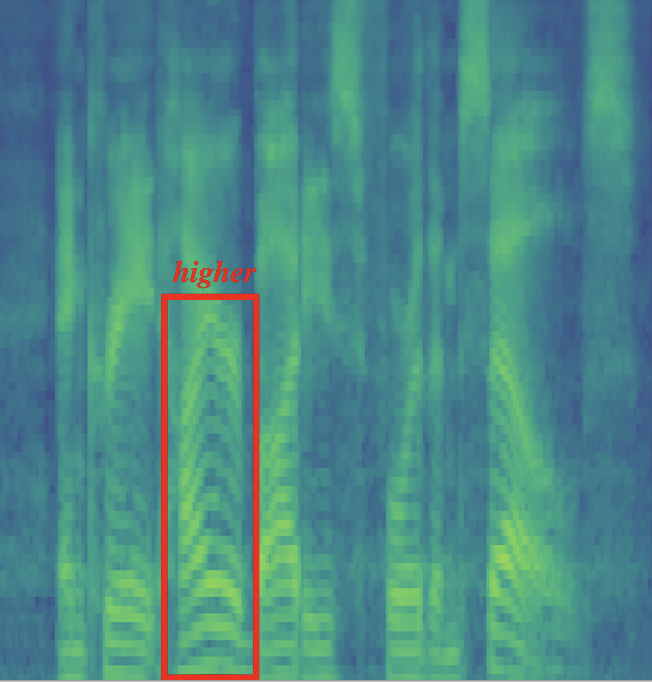
Case Study: Prosody Transfer
We use the text encoder of CLAPSpeech to extract the text prosody encoding of s7 and s8, then replace the text token encoding of “higher” in s8 with that in s7. The text of s7/s8 are shown in the table below.
sentence
text
s7 (reference)
Higher up could be seen some chinamen.
s8 (source/transfered)
And create higher bodies for themselves!
We provide the audio and mel-spectrogram of the reference, source, and transferred sample in the following table. We can hear that by editing the text encoding of “higher” in the source sample, the prosody pattern of “higher” in the reference (the pitch contours in reference remain flat in the early stage and then rise in the late stage) has been successfully transfered into the transfered sample. The successful manipulation of the local prosody proves that our CLAPSpeech extract prosody representation effectively influences the prosody prediction of the TTS system.